Importing structured qualitative data into Quirkos
While most qualitative researchers will use unstructured sources of data for their analysis, there are often times when you need to bring in data from structured interviews or surveys. Quirkos has tools and features that specifically help you manage these types of sources.


While most qualitative researchers will use unstructured sources of data for their analysis, there are often times when you need to bring in data from structured interviews or surveys. Quirkos has tools and features that specifically help you manage these types of sources.
When you start a project in Quirkos, there are two options: password protection and structured project. This is a feature that must be toggled when you start a project, and can’t be added retrospectively. Essentially it creates a project where each source can be split up into multiple ‘questions’. These are sections of sources which have common responses across all responses brought into the project. For example, both survey questions and structured questionnaires will ask the same question to each respondent.
Using the structured question project, you only have to put in the question once, but have different responses for each source. So if you’ve asked everyone ‘What do you think of our service?’ you can quickly see the answer in each source. It also allows you to quickly skip to the answer of each question, with a drop down and arrows to move between questions and answers.
There are two ways you can bring structured data like this into Quirkos: from spreadsheet or tabulated data in a CSV file, but also from text files.
The CSV approach relies on you having data in a spreadsheet format. This is likely to come from either an Excel spreadsheet you have entered data into, or a online survey platform such as SurveyMonkey or eSurv.org. Quirkos assumes this kind of data is formatted so that rows in the spreadsheet represent participants or respondents, one for each row. The first row should be the headings for columns that store different attributes, like name, age, or open ended responses to be analysed qualitatively.
Quirkos allows for mixed method data to be imported in this way at the same time as the qualitative data. You can have discrete or numerical data, properties/attributes (like age and gender) and also metadata, such as dates of interviews, how long people took to answer surveys etc. Quirkos will take discrete or mixed method data as properties for each of your sources. The open-ended longer text responses will be brought in as questions.
When formatting the spreadsheet for bringing data into Quirkos, you can show which columns represent open-ended qualitative data by having the header row for that column end with a question mark (?). Quirkos will assume that columns headers that end with a question mark represent qualitative data, and others represent data to be treated as properties. So fields like
| Age | Location | Gender |
Will be brought in as properties for each source, while
| What did you like about this? | How can we improve this? |
Will be brought in each as an answer for a separate question.
Once you have a formatted your data in any spreadsheet software (like Excel, LibreOffice or Google Docs) you need to save this as a CSV file. This is a standard file format for spreadsheet or tabulated data, and many survey platforms will save in this format. Quirkos needs to have the CSV file saved with a couple of options, which you should be able to choose when saving in the CSV format. Quirkos needs UTF-8 encoding, and will use the comma , as the field delimiter, and the single quotation mark ‘ as the text delimiter. While Office 365 is fine, older versions of Excel do not save in this format by default, forums here, here and here might help.
To import CSV files into Quirkos, first create a new project with the ‘Structured Questions’ option, then choose the Click to Add Source > button on the top right, then Import Sources as CSV.
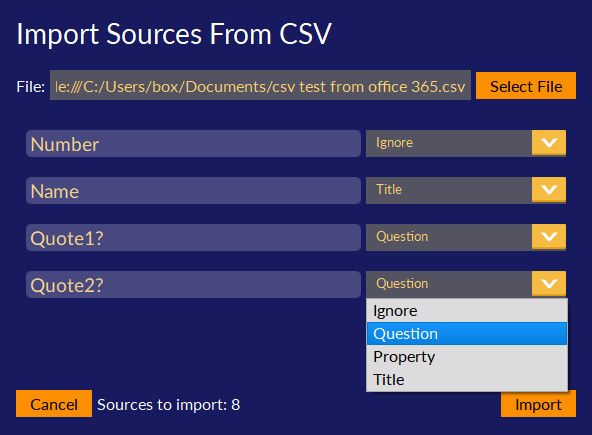
The field names from the file (the top row of each column) will be shown on the left, and there is a drop-down option box on the right that shows how each column of data should be treated. The options are Ignore (so that column is not imported), Question (for long-form open ended text responses), Property (for attributes or data to be imported as a source property) or Title such as Sam or Respondent3 (which will use the data in the column as the name of the source). At the bottom of the dialogue, it will also show how many rows of data have been detected as sources. If this number is not what you expect, or after importing the data some is missing, or split across sources, it is likely that the CSV file was not saved in the right format. Clicking Import will begin the import process, this may take a few minutes for large files.
You should now be able to see all the different rows of data as sources, with questions in the text tab, and properties in the properties tab for each source. Along the top of the sources column (right side of the screen) there should be tabs for each source, and clicking on the [ ] source browser button to the right of the tabs will show a list of all the sources in the project.
It is also possible to bring in data in structured questions from text files. When you have asked the same question in the same order across all your sources (for example transcripts of structured interviews, or survey responses). You can bring these in as Word documents (saved as docx files), text, rich text or PDF files.
For Quirkos to be able to identify the Questions and Answers, these need to be clearly formatted in a consistent way in the source. When you click on the ‘Import Source: Single File’ option under the Add Source button in the top right of a structured project, you’ll see the screen below:
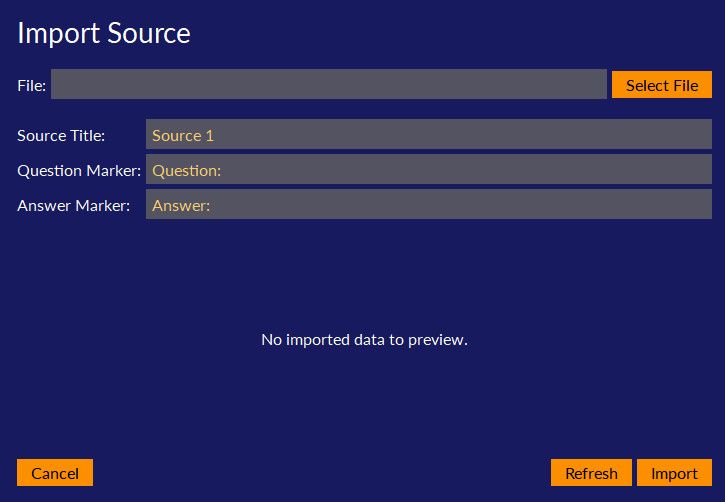
Before selecting a file, make sure that the Question Marker and Answer Marker match how you have identified these sections in your text source. By default, Quirkos assumes a layout like this:
Question:
What do you think about this?
Answer:
I think it’s really helpful.
Question:
How can we make it better?
Answer:
It’s already pretty great!
The spacing between the Question and Answer doesn’t matter, Quirkos is looking for the ‘Question:’ and ‘Answer:’ part of the source to show it where the question and corresponding answer is. However, you can also change the marker, so if you had used ‘Q:’ and ‘A:’, or even ‘Interviewer: and Sarah:’ you can change this in the option box before you open the source. You can also change the title of the source to be imported here, for example Sarah or Participant 1. You can only bring in one text file at a time with this approach, which allows you to have different sources formatted slightly differently (for example with a different participant name). Note, that the document must ask exactly the same questions, in exactly the same order, otherwise Quirkos will see these as new additional questions.
There’s a video tutorial here that takes you step by step through using both the structured CSV and text file import:
Hope this was helpful, if you haven’t tried Quirkos already you can download the full version here, and try for free. You’ll see how easy it is to learn, and how it can help you structure and master your qualitative data.