A priori coding is A-OK!
There are many different ways of coding qualitative data. Two of the most frequently mentioned are in vivo coding, in which participants’ actual words become codes while the researcher is coding, and a priori coding, in which the researcher has defined codes before beginning to analyze the data.


A warm welcome to Kimberly Hirsh with her first of many blog posts for us!
There are many different ways of coding qualitative data. Two of the most frequently mentioned are in vivo coding, in which participants’ actual words become codes while the researcher is coding, and a priori coding, in which the researcher has defined codes before beginning to analyze the data.
It can feel as though in vivo coding is the One True Way to analyze qualitative data. In my own studies, professors emphasized in vivo coding as a way to stay close to the data and mitigate researcher bias. There are times, however, when using a priori coding makes more sense. In The Coding Manual for Qualitative Researchers, Johnny Saldaña (2015) points out that the choice of coding type should depend on the goals of the study.
The research paradigm or theoretical approach may necessitate a particular type of coding. Both grounded theory and ethnography seek to explore a phenomenon or culture and describe it from participants’ perspectives. For these purposes, in vivo coding is most appropriate.
At other times, however, a priori coding meets the goals of the research better. This is especially the case when the researcher seeks to validate or revise a conceptual or theoretical framework based on previous literature. My current research uses an a priori coding scheme with Quirkos to validate Dr. Crystle Martin’s (2012) framework of information literacy.
Dr. Martin used an a priori scheme while conducting research on the information literacy practices of World of Warcraft players. Information literacy refers to
“the intellectual process of recognizing the need for information to solve a problem or issue regardless of setting, and working through the process in a manner that arrives at information that fulfills the given need to the satisfaction of the seeker” (Martin, 2012, p. 7).
Dr. Martin drew on prior material, a collection of documents describing different organizations’ information literacy education standards, to create a conceptual framework of information literacy practices. She used this framework to create an a priori coding scheme describing a variety of information literacy practices. She used this coding scheme to investigate which information literacy practices described in standards are actually present in World of Warcraft community spaces online. Dr. Martin updated the conceptual framework based on her findings and created an updated coding scheme reflecting the updated framework (see Table 1).
I am using this updated coding scheme to investigate the information literacy practices of cosplayers, people who dress in costumes as beloved characters as either a hobby or a profession. Applying Dr. Martin’s framework to a different population has the potential to enhance the framework’s validity. Dr. Martin found that World of Warcraft players use a variety of information resources and many of the practices identified by standards, as well as practices not mentioned in the standards. My research explores how cosplayers use information literacy practices to identify elements for a particular cosplay, learn construction techniques for costumes and props, and share what they learn with other cosplayers.
Table 1
Martin’s Information Literacy Coding Scheme (2012, p. 84)
Saldaña (2015) suggests that researchers create a codebook, whether conducting in vivo or a priori coding, that includes each code, a description of the code, and an example of data coded with that code. He also points out that computer-assisted qualitative data analysis software facilitates this by maintaining a list of codes and providing space to define them. Quirkos is no exception.
How to create an a priori coding framework in qualitative software
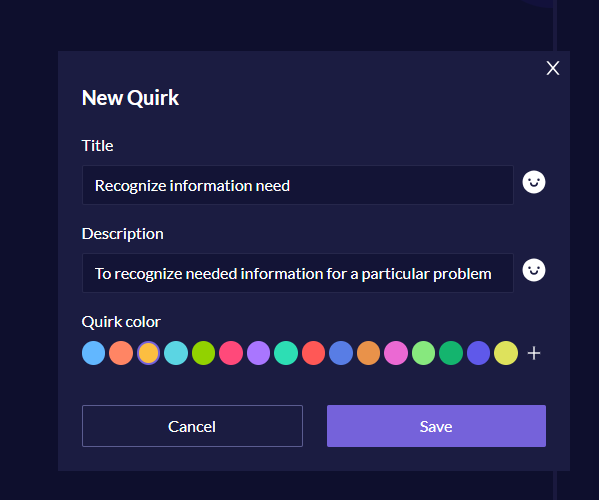
It’s easy to create a codebook with a priori codes in Quirkos. Here’s how I did it.
First, I created and defined each code:
With all the codes on the canvas (2), I can hover over any code to see its definition (3).
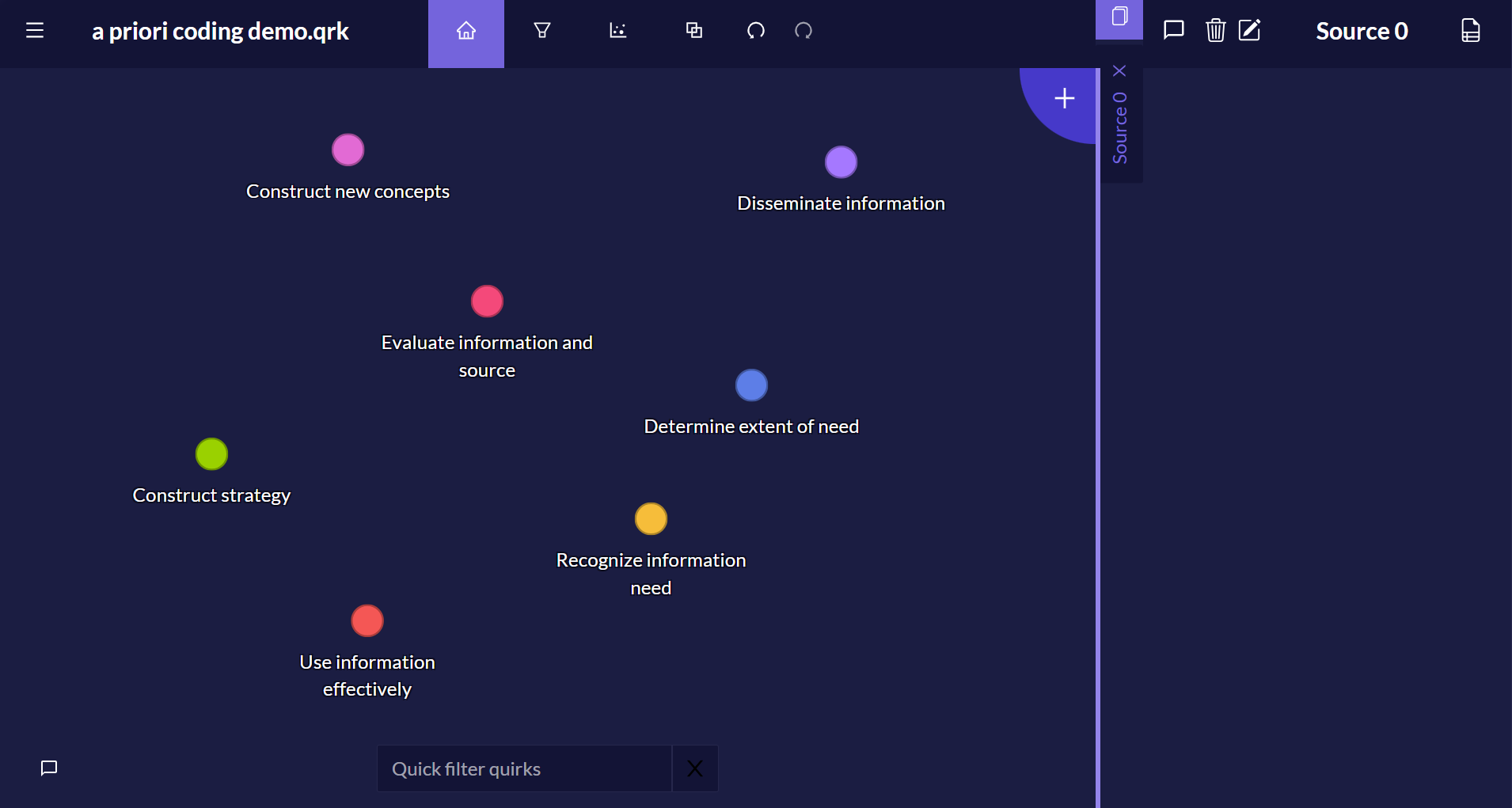

I was now ready to bring in data sources and code them as usual. At any point, I can go back and add a specific example into the code description or simply view the coded segments as usual to see all of the segments coded with a given code.
It can feel like a priori coding doesn’t count as “real” qualitative data analysis, but if you use it for the right research purpose and document your definitions and how you derived the codes, it can be just as valuable as in vivo or any other coding approach for the research purposes appropriate to it.
Quirkos can help you apply your a priori coding framework, and make qualitative analysis fun and engaging! Start your free trial today!

References
Saldana, J. (2015). The coding manual for qualitative researchers. SAGE.