In vivo coding and revealing life from the text
Following on from the last blog post on creating weird and wonderful categories to code your qualitative data, I want to talk about an often overlooked way of creating coding topics – using direct quotes from participants to name codes or topics


What is in vivo coding?
In vivo coding is a type of qualitative coding where direct quotes from participants are used to name the codes or topics. This is sometimes called “in vivo” coding, from the Latin ‘in life’, and not to be confused with the ubiquitous qualitative analysis software ‘NVivo’ (which can be used for any type of coding, not just in vivo!).
In vivo coding is really a type of grounded theory, where your codes and theory are drawn directly from the data.
Following on from our last blog post on creating weird and wonderful categories to code your qualitative data, I want to talk about this great and often overlooked way of creating coding topics.
How to do in vivo coding
With in vivo coding, a researcher will create a coding category based on a key phrase or word used by a participant. For example, someone might say ‘It felt like I was hit by a bus’ to describe their shock at the event, and rather than creating a topic/node/category/Quirk for ‘shock’, the researcher will name it ‘hit by a bus’. This is especially useful when metaphors like this are commonly used, or someone uses an especially vivid turn of phrase.
In vivo coding doesn’t just apply to metaphor or emotions, and can keep researchers close to the language that respondents themselves are using. For example when talking about how their bedroom looks, someone might talk about ‘mess’, ‘chaos’, or ‘disorganised’ and their specific choice of word may be revealing about their personality and embarrassment. It can also mitigate the tendency for a researcher to impose their own discourse and meaning onto the text.
In an older article I talked about having a category for ‘key quotes’ - those beautiful times when a respondent articulates something perfectly, and you know that quote is going to appear in an article, or even be the article title. The in vivo approach takes this even further, allowing more of your analysis to be led by what is actually in your qualitative data.
What is the difference between in vivo coding and a priori coding?
While in vivo coding uses your data sources verbatim to generate codes, the codes in a priori (or framework) coding are decided in advance, and often informed from existing theory, before the analysis of sources begins.
In a way, you could consider that if in vivo coding is ‘from life’ or grows from the data, then framework coding (or a priori coding) to an existing structure is more akin to ‘in vitro’ (from glass) where codes are based on a more rigid interpretation of theory. This is just like the controlled laboratory conditions of in vitro research with more consistent, but less creative, creations.
Risks and challenges of in vivo coding
There are some problems you may encounter when trying to interpret the data from in vivo codes. If an in vivo code was named only from one source, how ubiquitous will it be across everyone’s transcripts? If someone talks about a shocking event in one source as feeling like being ‘hit by a bus’ and another ‘world dropped out from under me’, would we code the same text together? Both are clearly about ‘shock’ and would probably belong in the same theme, but does the different language require a slightly different interpretation? Wouldn’t you lose some of the nuance of the in vivo coding process if similar themes like these were lumped together?
The answer to all of these issues is probably ‘yes’. However, they are not insurmountable. In fact, Johnny Saldaña suggests that an in vivo coding process works best as a first reading of the data, creating not just a summary if read in order, but a qualitative framework from each source which should be later combined with a ‘higher’ level of second coding across all the data. So after completing in vivo coding, the researcher can go back and create grouped coding categories based around common elements (like 'shock') or/and conceptual theory level codes (like 'long term psychological effects') which resonate across all the sources.
How to pair in vivo coding with a priori coding
Pairing in vivo and a priori methods may seem like a very time consuming process, but in fact multi-level coding (which I often advocate) can be very efficient, especially if you use in vivo coding in your first 'pass' through the data. It may be that you just highlight some key words, on paper or in Word, or create a series of columns in Excel that is adjacent to each sentence or paragraph of source material. Since the researcher doesn’t have to ponder the best word or phrase to describe the category at this stage, creating the coding framework is quick. It’s also a great process for participatory qualitative analysis, since respondents can quickly engage with selecting juicy morsels of text.
Don’t forget, you don’t have to use an exclusively in vivo coding framework: just remember that it’s an option to use for key illuminating quotes alongside your other codes. Again, there is no one-size-fits-all approach for qualitative analysis, but knowing the range of methods allows you to choose the best way forward for each research question or project.
Using qualitative software for in vivo coding
Qualitative software makes it easy to keep all the different stages of your coding process together, including in vivo coding. You can easily create new topics by splitting and merging existing codes. While the procedure will vary a little across the different qualitative analysis packages, the basics are very similar, so I’ll give a quick example of how you might do this in Quirkos.
Step 1: Create a new in vivo code.
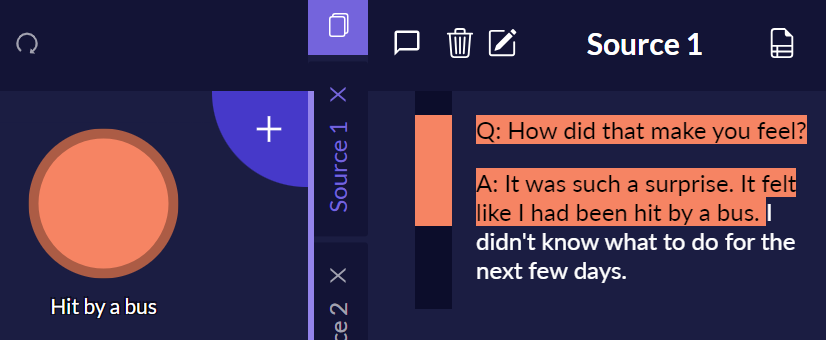
You can create a new Quirk/topic in Quirkos just by dropping a section of text directly onto the canvas, so this is a good way to create a lot of themes on the fly, as with in vivo coding. Just name these according to the in vivo phrase, and make sure that you highlight the whole section of relevant text for coding, so that you can easily see the context and what your respondent is talking about.
If you anticipate that you'll have lots of in vivo codes that may only get coded once, it can also be helpful to create them as memos first, before you go on to focus on just a select few, or create your higher-level themes as Quirk bubbles.
Step 2: Create higher level codes or groups to organise your in vivo codes.
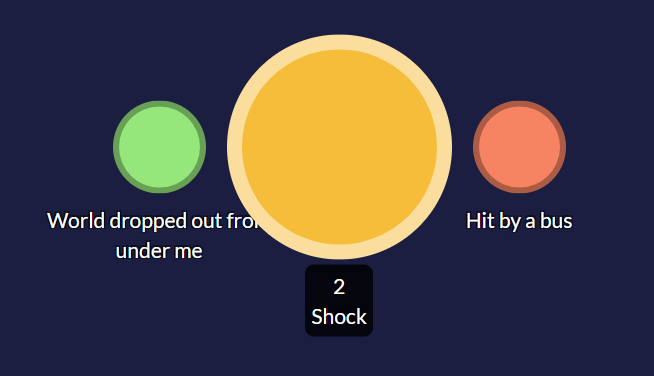
Once you have done a full (or partial) reading and coding of your qualitative data, you can work with these codes in several ways. Perhaps the easiest is to create a umbrella (or parent) code (like 'shock') to which you can make relevant in vivo codes into subcategories, just by dragging and dropping them onto the top node. Now, when you hover over the main node, you will see quotes from all the in vivo subcategories in one place.
It’s also possible to use the Groups feature in Quirkos to group your codes: this is especially useful when you might want to put an in vivo code into more than one higher level group. For example, the ‘hit by a bus’ code might belong in ‘shock’ but also a separate category called ‘metaphors’. You can create groups from the Quirk Properties dialogue of any Quirk, assign codes to one or more of these groups, and explore them using the query view. Our Quirkos tutorial pages explain this process in greater detail.
Step 3: Narrow your focus for analysis.
It’s possible to save a snapshot of your project at any point, and then actually merge codes together to keep them all under the same Quirk. You will lose most of the original in vivo codes this way (which is why the other options are usually better) but if you find yourself just dealing with too many qualitative codes, or want to create a neat report based on a few key concepts, this can be a good way to go. Just right click on the Quirks you want to keep, and select ‘Merge Quirk with...’ to choose another topic to be absorbed into it. Don’t forget all actions in Quirkos have Undo and Redo options!
In vivo coding: example with video
We have a video tutorial on using in vivo coding, and using the memo features in Quirkos to make this easier:
How to practice in vivo coding with qualitative software
We don’t have an example dataset coded using in vivo quotes, but if you look at some of the sources from our Scottish Independence research project or our Qualitative Researcher Journeys project, you will see some great comments about politics and academia that leap out of the page and would work great for in vivo coding.
So why not try it out, and give in vivo coding a whirl with the free trial of Quirkos: affordable, flexible qualitative software that makes coding all these different approaches a breeze!

Recommended reading on in vivo coding
This method is discussed in more depth in Johnny Saldaña’s book, The Coding Manual for Qualitative Researchers, which also points out how a read-through of the text to create in vivo codes can be a useful process to create a summary of each source.
Ryan and Bernard (2003) use a different terminology called indigenous categories or typologies, after Patton (1990). However, here the meaning is a little different – they are looking for unusual or unfamiliar terms which respondents use in their own subculture. A good example of these are slang terms unique to a particular group, such as drug users, surfers, or the shifting vernacular of teenagers. Again, conceptualising the lives of participants in their own words can create a more accurate interpretation, especially later down the line when you are working more exclusively with the codes.