Open and Axial Coding Using Qualitative Software
Many forms of grounded theory adopt a variant of open, axial and selective coding as their key steps in qualitative analysis. Usually these follow the description in Strauss and Corbin (1990), but others such as Glaser (1978) defined similar procedures


What is open, axial and selective coding?
Roughly speaking, open coding involves techniques to describe and conceptualise the data at a very basic level, on small parts of the data, often a line-by-line basis. It is kind of like breaking down the data into the smallest components, so that they can later be brought back together in a greater conceptual level in axial coding. Axial coding is where connections between the open codes are examined, and used to create larger codes or eventually themes (in the selective coding step).
However, as Vollstedt and Rezat (2019) note, “the procedures are neither clear-cut, nor do they easily define phases that chronologically come one after the other”. As always in qualitative analysis, there is no one-size-fits-all approach, or step-by-step procedure to ‘do’ any analytical method. It’s up to the researcher to examine their methodological and phenomenological beliefs, explore the different analytic approaches, and decide which best applies to their data and research questions.
Many forms of grounded theory adopt a variant of open, axial and selective coding as their key steps in qualitative analysis. Usually these follow the description in Strauss and Corbin (1990) which specifically used these terms. Others such as Glaser (1978) defined similar procedures using the terms ‘Substantive coding’ and ‘Theoretical coding’. Charmaz (2006/2014) uses the term ‘Initial Coding’ which could be seen as similar to open coding, followed by axial coding as one possible approach in the secondary ‘Focused coding’ or ‘Theoretical integration’ stage.
These descriptions are not entirely equivalent, and are not necessarily performed in this strict order; in fact there may be several iterations of each in a cyclical coding process. But regardless of the origin or specifics, open and axial coding seems to have become an analytic method in their own right, which many use to structure and conceptualise their coding process.
If applying ‘grounded theory’, students should quickly discover the breadth of concepts and procedures that exist under this umbrella and note the numerous possible ways to implement it at the analysis stage. That’s why (as always) I want to note that my descriptions can only be a crude simplification, and you should always refer back to the wider literature and reference list at the end of the article before applying any of them!
Open and axial coding in qualitative software
Some commentators claim that qualitative data analysis software (also known as CAQDAS or QDAS) doesn’t support open, axial or selective coding approaches, or that particular packages are (or are not) designed to support particular strategies. Usually, these claims are pretty debatable: I’ve seen all kinds of different techniques used in all kinds of different software. They are all flexible enough that you can use them with most analytic approaches, and none of the major packages suggest they were designed to privilege one over the other.
But I’m often asked, "How do you do open and axial coding in Quirkos?" It’s a good question, but also a difficult one since I’ve seen so many different variants on these approaches. It’s also the reason that no qualitative software packages have buttons or wizards marked as ‘Open and Axial Coding Mode’ – the definitions and implementations of these steps are too varied to have one approach.
To that end, I’m going to describe a few ways that you can use various tools in Quirkos to do open and axial coding. While some of these are Quirkos specific, the basic operations are possible in most qualitative analysis software (with some variations) so might be useful as a generic guide.
Open coding with memos

A common way to do open coding on paper is to use notes in the side of a printed transcript to identify codes or do some variant of line-by line or in-vivo coding. In Quirkos, you can use the Memos column to do the same thing. Select a line, or part of the text that’s interesting, and drag and drop it onto the memo column. A little ‘sticky note’ will appear, and you can start typing in it. Unlike on paper, there’s no limit to how many annotations you can make like this, or how long they can be. You can also delete or edit them at any time. Any time you view that section of text, be it as part of the whole source, or later as part of a view with just some sections of text, you will be able to see your memos. You can also export these as a table or report with both the source text and memo side-by-side.
Open coding with codes

Many textbook examples show the open coding process as creating a long list of ‘emergent codes’, fairly specific descriptors, labels or tags that summarise a section of text. At this initial stage in grounded theory, the idea is often not to think too hard, with descriptors that are too conceptual like ‘Notions of self’ but simple things like ‘Positives’ or ‘Motivations’.
In Quirkos you can do this by creating dozens of codes (quirk bubbles) on the fly, sometimes even unique ones for each line of text. You can do this by dragging and dropping a section of text onto the canvas or clicking the New Code button at the top-right of the canvas, which will create a new code with that text in it. Just give it a name, change colour or description if needed, and then move on to the next section of text. Obviously, if you have concepts that reoccur, you can add these to existing codes. This process is often (incorrectly) seen as the core element of grounded theory – creating codes or themes as they ‘emerge’ from the data.
Open coding with a single code

Some researchers don’t like to create themes or codes too early in the analytic process. (In another of our blog posts, we cover why you might want to avoid creating your codes/themes too early.) Since the first readings of the data should be about familiarity and getting close to the data, trying to apply a structure by interpreting and creating codes can lead to a reductive approach, which tries to abstract the data before it is fully understood in context. This is one of the frequently levelled criticisms of qualitative analysis software – the idea that ‘it forces you to code’, with many instead preferring pen and highlighters. However, this is not true. As seen with the memo approach, you can do the whole analysis in qualitative software without creating a single code if you choose.
But while reading through the data, you’ll obviously find exciting and interesting sections of text you want to remember and come back to. On paper transcripts, you might underline these or use a highlighter so you can quickly see these when skimming through the data in a later session. However, these are not necessarily conceptualised like codes; they are just interesting things to come back to.
In qualitative software you can do the same thing using a single blank code! Just create one ‘code’, with the colour of your choice, and use it to capture anything you would want to highlight or underline of interest – dragging and dropping text onto that one code. This code doesn’t have to have a name, or it can be called ‘Highlights’ (as in our example above) or something vague. But that way, when you want to come through and read the data again (possibly with a view to coding it) you’ll have a quick visual way to see the interesting bits. In Quirkos, you can export a Word file of your transcripts like this, just with your colour coded highlights.
But if you are in a rush or looking for a few particular themes, you can also code your highlighted sections, without rereading the whole dataset. All the ‘uninteresting’ bits of data will be skipped (although they're still there if you want them), but you can start creating more codes, and adding your ‘interesting’ data to more specific themes like ‘Barriers’ or ‘Positives’. This might be part of an extended open coding, or even straight to axial coding process.
Of course, you can also use more than one code for highlighting – many find 4 or 5 colours of highlighters useful for a first read, especially to do basic descriptions of a few major categories, like positive (green) or negative (red) things. For me, one of the main advantages of qualitative software like Quirkos is that you can’t run out of colours! But it can be helpful to limit a first ‘open’ coding read through to a few very basic themes like this, just as if you were restrained by highlighter colour. The advantage of having done this in software (rather than on paper) is that it is then very quick to find everything on one topic (colour) from all the sources, and also to change your mind, build on your highlighting later, and mark something with more than one colour.
Axial coding with codes
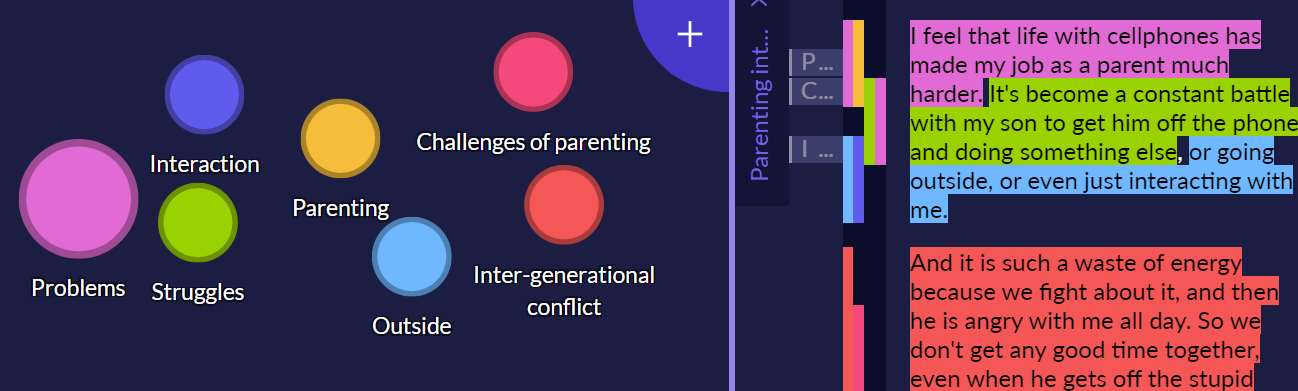
If you used memos instead of codes for the open (or initial) coding and read-through, axial coding may be the stage that you choose to start actually creating codes. As you read through your data for a second time, you can code from your memos in Quirkos. Just click on a memo, and it will select the relevant section of text so you can drag and drop it onto an existing or new code. You’ll usually find this process goes from a large number of very varied memos to a smaller number of codes which are more general than the memo observations. This helps build up to a higher level of categorisation of the data, and lets you keep track of the quotes that support the development of each code.
Also remember that your code bubbles don’t have to have data in them! You can use them in Quirkos to create a mind-map, since you can move and group them around, and conceptualise things as they emerge from the data.
Axial coding with hierarchies
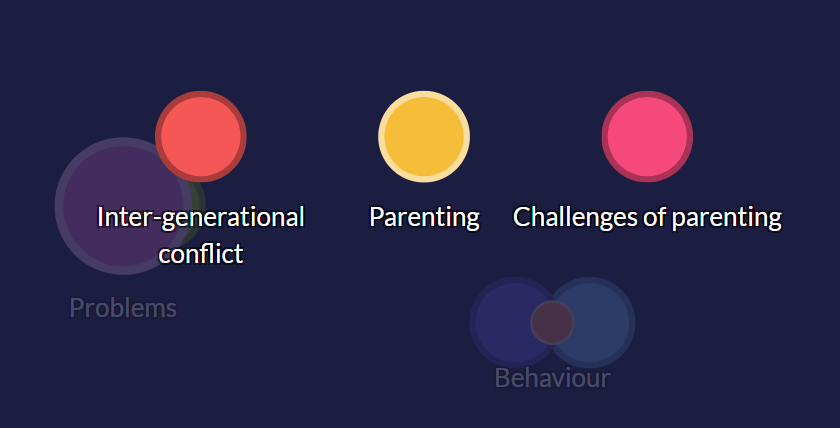
If you already have codes, one way to start creating connections and wider categories is to start grouping them together in some way. In Quirkos you can create subcategories of codes just by dragging a code onto another. But you can also create looser groupings by just having codes placed close to each other. This is a really useful way to do axial (or higher level coding), as you can gradually put codes closer together as they start to form part of a common theme. Some themes might be created as new ‘codes’ as the parent node, but others may grow from existing open codes.

Axial coding with groups
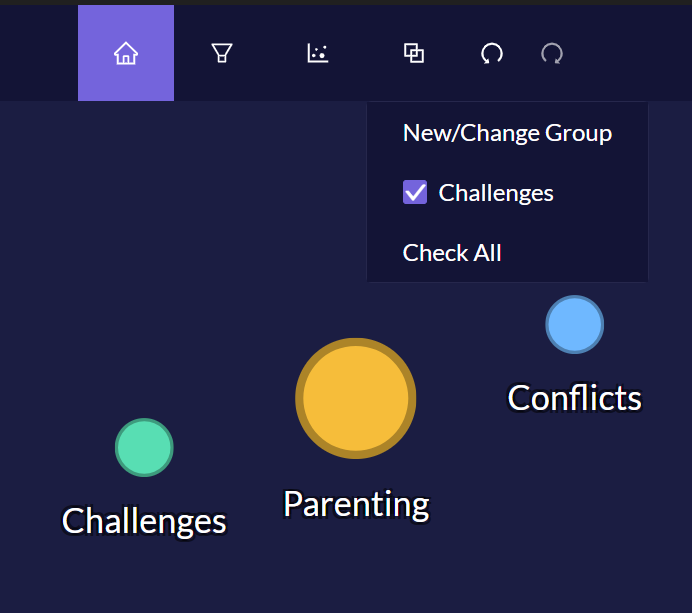
In Quirkos, you can also create code ‘groups’ where one code can belong to one or more (or zero) groups. This allows you to create non-hierarchical groupings ideal for the higher-level concepts in the axial coding stage. The difference here is that you can turn groups on and off, so that you can focus on one or more groups at a time. In the above example, we have filtered the canvas so it only shows the 'Challenges' group of codes. Groups can therefore also be useful if your project has multiple types of coding (such as thematic, discourse, IPA) and codes that belong to each approach. You can then turn on or off certain types of coding, while preserving codes that are common across them. You can also create two groups, one for 'open codes', and another for 'axial codes', if working in this way.
In Quirkos, click the Groups button and then 'New/Change Group' to create a new group, and right click on a quirk and choose 'Edit' to assign it to one or more of the created groups.
Selective coding and higher-level categories
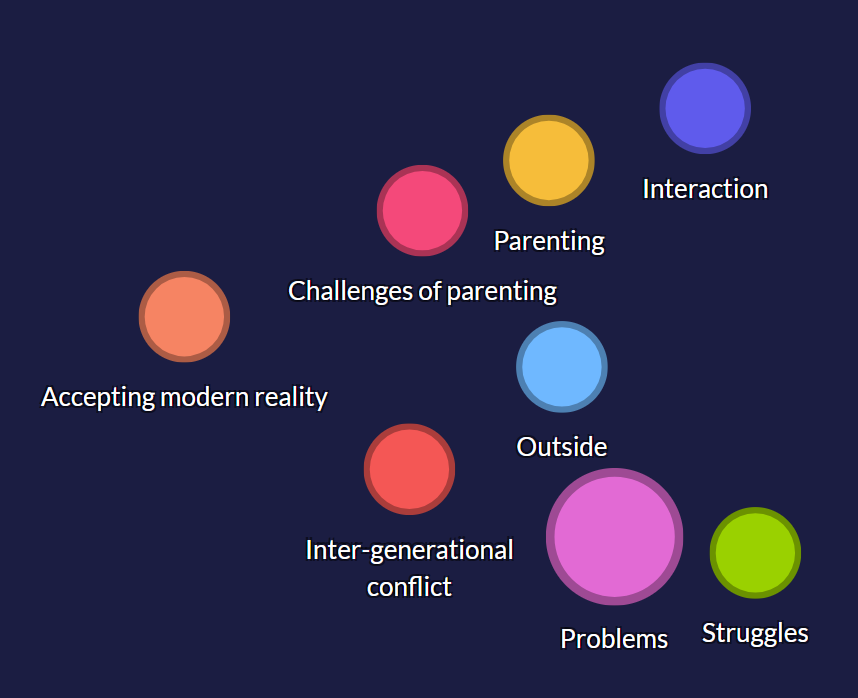
Once open and axial coding has been attempted, qualitative researchers may try to move on to selective coding, where they are looking for a cohesive theme that can be used to answer the research question. Again, in qualitative software there is no limit to the levels of coding that can be registered and practically managed, and selective coding can be done with any of the hierarchy or grouping techniques above to move towards a unified theory. Again, the software allows for a great deal of experimentation in this regard, as codes and themes can be easily created, developed or rejected (with full undo and redo!).
Quirkos also has specific tools to help higher-level categorisation, letting you visualise how often codes are overlapping on sections of text (using the Overlap view).

Remember not to get carried away with creating too many abstract themes or codes! The coding process is a tool to help you better read and understand the data, make connections and get to an understanding of your participant’s world that will help you answer the research questions. And if this article has you intrigued to try using Quirkos for your own analytic journey, you can start a free trial and get going today!

References
Charmaz, K., 2006, Constructing grounded theory: A practical guide, Sage, London
Glaser, B. G. (1978). Theoretical sensitivity: Advances in the methodology of grounded theory. Mill Valley: Sociology Press.
Savin-Baden, M., Howell Major, C., 2013, Qualitative Research: The essential guide to theory and practice, Routledge, London
Strauss, A. L., & Corbin, J. M. (1990). Basics of qualitative research: Grounded theory procedures and techniques. Thousand Oaks: Sage Publications.
Vollstedt, M., Rezat, S., 2019, 'Compendium for Early Career Researchers in Mathematics Education', in An Introduction to Grounded Theory with a Special Focus on Axial Coding and the Coding Paradigm, Springer, London
Header image by Clint Budd